See libraries at Perceptual Hashing Libraries
Key Points of "Introduction to Perceptual Hashes: Measuring Similarity" by Alcides Ramos on Apiumhub
- Simity vs. Identity: Checking if files are identical is straightforward, but comparing the similarity of file content is more complex due to factors like compression and resizing
- Perceptual Hashes (pHashes): These algorithms are designed to minimize changes for similar inputs. Popular image hashing algorithms include aHash,Hash, pHash, dHash, bHash, wHash, and ColorMoment Hashing.
- pHash Algorithm: Uses Discrete Cosineform (DCT) to transform data from the spatial domain to the frequency domain. The Hamming distance is used to compare images based on the number of different bits in hashes.
- Use Cases:
- Digital Rights Management: Protect intellectual property and manage multimedia data.
- Dataeduplication: Prevent duplicates in datasets, optimizing storage and costs.
- Reverse Image Search Engine: Enable users to find products bying a photo.
- DNA Sequencing: Reduce data size for massive searches and comparisons.
- **Detecting Diseases Use image processing techniques based on pHashes to detect leaf diseases in agriculture.
- Implementation Example: Demonstrates how to use the
jensgers/imagehashlibrary in PHP to compute and compare perceptual hashes of images. - Examples: Illustrates how the Hamming distance be calculated from binary hashes of two images, showing different distances based on image similarity.
This summary captures the essential points about perceptual has, its applications, and a practical implementation example.
Introduction to Perceptual Hashes: Measuring Similarity - Apiumhub
Alcides Ramos
9–11 minutes
Introduction
Checking if files are identical is an exceedingly-trivial task – it is possible to directly compare all their bytes or perhaps compute a hash of each file and compare those values -but trying to compare the similarity of files’ content is entirely more difficult.se, greatly reducing the space needed for evaluation.
What does similarity mean?
How can a computer determine whether two photos contain the same content after getting resized or compressed several times?
Due to the lossy nature of most image compression algorithms, it is impossible to compare the bytes of images to determine whether they have the same content.
Every time a JPEG image is decoded and encoded, additional data is changed or lost. While formats like PNG are lossless, resizing images will also change their content, preventing direct comparisons.
There are a variety of image hashing algorithms, some of the most popular algorithms being:
- Average Hashing (aHash)
- Median Hashing (mHash)
- Perceptual Hashing (pHash)
- Difference Hashing (dHash)
- Block Hashing (bHash)
- Wavelet Hashing (wHash)
- ColorMoment Hashing
Cryptographic hashing algorithms like the MD5 or SHA256 are designed to generate an unpredictable result. In order to do this, they are optimized to change as much as possible for similar inputs. Perceptual Hashes are the opposite —they are optimized to change as little as possible for similar inputs.
pHash algorithm computes hashing on top of Discrete Cosine Transform (DCT) that transforms data from spatial domain to frequency domain.
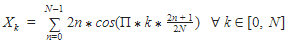
Perceptual Hashes (pHashes)
As previously noted, this family of algorithms are designed to not change much when an image undergoes minor modifications such as compression, color correction and brightness. pHashes allows the comparison of two images by looking at the number of different bits between the input and the image it is being compared against. This difference is known as the Hamming distance.
A very simple way of using this algorithm would be to create a list of all known images and their perceptual hash. A hamming distance can be calculated with just a xor and popcnt instruction on modern CPUs. This approach would be fairly fast to start with. With tens of thousands of images, it could be possible to get results in a few seconds, which is likely acceptable performance.
When the amount of images starts growing to the millions, sequentially scanning and comparing against every image takes far too long. Because the hash has to be computed against the input each time, a conventional index would not be usable.
Thankfully, a BK-tree -a tree specifically designed for metric spaces like Hamming distance- can be used here instead of having to search against every image in the database, greatly reducing the space needed for evaluation.
How does pHashes work?
Here is a demonstration of how pHash works using the following image as source:

The pHash algorithm initially calculates the gray value image and scales it down.

This case uses a factor of 4, which is why the image is scaled down to 84×84, that is, a 32×32 image.

To this image, a discrete cosine transform is applied, first per row…

… and afterwards per column

The pixels with high frequencies are now located in the upper left corner, which is why the image is cropped to the upper left 8×8 pixels.
Next, calculate the median of the gray values in this image
And finally, generate a hash value from the image.
1010010010101101100110011011001101100010100100000111011010101110
Some relevant use cases
Digital Rights Management
Intellectual property rights protection and management of multimedia data is essential for the deployment of e-commerce systems involving transactions on such data.
Early detection of resources under copyright avoids complex and expensive legal issues
Data deduplication
pHash gives a metric about the similarity between two sources, which prevents duplication in the main dataset.
Optimizing the main dataset is not only an improvement in terms of curated contents, but also in terms of costs of infrastructure.
Reverse image search engine
E-commerce is a growing industry that has become a notable part of many consumers’ habits; therefore, many sites are trying to bring new features to the filtering and comparison tools to improve the user experience. One such feature is allowing customers to find products by a photo in order to suggest the exact match in case of success or the most similar products in other cases. This is called a reverse image search engine.

DNA sequencing
Each nucleotide is encoded as a fixed gray level intensity pixel whose hash is calculated from its significant frequency characteristics. This results in a drastic data reduction between the sequence and the perceptual hash, allowing scientists and geneticists to perform massive searches and compare millions of combinations with low infrastructure impact.
Detecting signs of disease
In the field of agriculture, there are many destructive diseases, for example leaf diseases that are the most frequent diseases where spots occur on the leaves. If these spots are not detected on time, they can cause severe losses. To detect leaf disease, image processing techniques are employed, many of them based on pHashes.
Implementation in PHP
$ composer require jenssegers/imagehash
<?php
[...]
use Jenssegers\ImageHash\ImageHash;
use Jenssegers\ImageHash\Implementations\DifferenceHash;
$hasher = new ImageHash(new DifferenceHash());
$hash1 = $hasher->hash('path/to/image1.jpg');
$hash2 = $hasher->hash('path/to/image2.jpg');
$distance = $hasher->distance($hash1, $hash2);
Example #1
| | |
| ---------------------------------------------------------------------------------- | -------------------------------------------------------------- | ---------------------------------------------------------------------------------- | -------------------------------------------------------------- |
| Image | Image |
| ! "Introduction to Perceptual Hashes: Measuring Similarity 10" | ! "Introduction to Perceptual Hashes: Measuring Similarity 11" |
| Image | pHash |
| 0011110000111110000011100001101000111010000111100001111000011110 | |
| 0011110000111110000011100011111000111110000111100001111000011110 |
A comparison of the binary hash reveals only 3 different bits, so the Hamming distance is 3.
Example #2
| | |
| ---------------------------------------------------------------------------------- | -------------------------------------------------------------- | ---------------------------------------------------------------------------------- | -------------------------------------------------------------- |
| Image | Image |
| ! "Introduction to Perceptual Hashes: Measuring Similarity 12" | ! "Introduction to Perceptual Hashes: Measuring Similarity 13" |
| Image | pHash |
| 00101000101010001010100010101000101010110010101101010010100010101000111100110111 | |
| 00101000101010001010100010101000101010110010101101010010100010101000111100110111 |
A comparison of the binary hash reveals 39 different bits, so the Hamming distance is 39.
